

The Promises and Perils of Algorithmic Governance
Governing algorithms and "through algorithms" puts Government tools to test

The promises and perils of big data cannot be understood without exploring algorithms, their nature and functioning. Without algorithms, big data remains powerless (Gritsenko and Wood, 2020). Without big data, algorithms lose much of their potential. Algorithms are nothing more than encoded procedures for solving a problem by transforming input data into a desired output (Gillespie, 2014), and as such, they have existed for a long time. What is now different is that, combined with the emergence of vast volumes of data, computing power, machine learning techniques and cloud storage systems, current algorithms can track behaviors of entire populations, and make and enforce decisions over those populations in real time.
The use of algorithms across sectors, from finance (e.g. to allocate funds, automate sale-purchase decisions or assess risk scores) to advertising (e.g. product recommendations) has now been widely covered. Algorithms are also being increasingly used by governments to perform a diverse set of functions such as issuing speed tickets, selecting packages for inspection in customs, deciding areas for police patrolling or allocating social benefits. This has given way to the term algorithmic regulation: the use of algorithmically generated knowledge to execute or inform decisions to manage risks or alter behavior to achieve some pre-specified goal (Yeung, 2018). Karen Yeung identifies two main forms of algorithmic regulation: (i) reactive, where an automated response is triggered based on algorithmic analysis of data, and (ii) pre-emptive, which infers predictions about future behavior based on algorithmic assessment of historic data. The result of the application of the algorithm can be an automated response (e.g. a fine) or a recommendation for someone to act upon (e.g. a proposal for a social benefit).
In the early optimistic days, thinkers like Tim O’Reilly (2013) described the potential efficiency gains of leaving regulatory decisions to algorithms. Decisions can be made much faster and, by eliminating discretion, they can also become more neutral and transparent. By now, the worries about the lack of neutrality of algorithms, bias in the data inputed in them, the problems embedded in the decision rules, and their harms to vulnerable groups has been identified and documented by many authors. As put by Janssen and Kuk (2016) “In effect, decisions produced by the algorithms are as good as the data upon which such decisions are computed and the humans and systems operating them.”
Danaher and co-authors (2017) provide a useful representation of the objections to algorithmic decision-making based on Zarsky (2016):
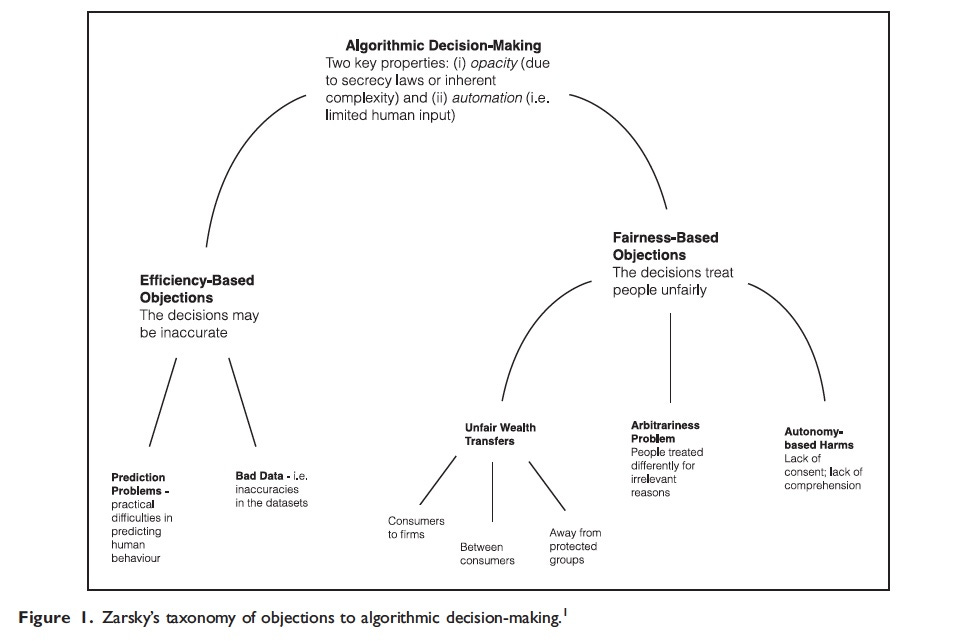
The promises and perils of the use of algorithms by private and public actors has important implications for governments. On the one hand, they need to develop the necessary capacities to make sure that private entities are not using algorithms to produce harms. On the other, in their own use of algorithmic regulation and decision-making, governments need to ensure that they can generate public value without producing negative impacts.
This means addressing the issues produced by the opacity and lack of human agency that are the defining features of algorithms. Efforts to increase the transparency and accountability of algorithms are multiplying. This report by The Ada Lovelace Institute, AI Now Institute and Open Government Partnership analyzes the initial wave of some of those initiatives. Although important, there is still a long way to go, and several challenges remain. Research about both the nature of algorithms and their effects is still nascent, and difficult. Kitchin (2017) points to three challenges that hinder research about algorithms: it is hard to gain access to their formulation, they are heterogeneous and embedded in wider systems, and their work unfolds contextually and contingently.
Despite these challenges, understanding algorithms, their effects, and the role and capacities of governments for algorithmic governance is key and connected to fundamental questions. For example, making specific algorithms more transparent or revisable does not eliminate the fact that “real time surveillance is critical to the operation of all forms of algorithmic regulation” (Yeung, 2018). Also, the debate over who should scrutinize algorithms and to what degree opens fundamental questions with implications around legitimacy and feasibility. Some, like Denis Roio, argue that “sovereignty should remain in the hands of the people who use [algorithms]” (2018). This is questionable, but reveals that, at the core, the debate about algorithmic governance cannot escape looking into the asymmetries of power embedded and reflected in the way algorithms are defined and operate.
Given algorithms’ ability to affect how power, authority and resources are generated, exercised and distributed, governments need to acquire the capacities that enable them to govern algorithms to generate public value in a legitimate and effective way.