

Is Data a Public Infrastructure?

Two weeks ago, I got to spend time with old friends at the GovTech4Impact world congress in Madrid. Listening to world experts like Dan Abadie, Aura Cifuentes, Mara Balestrini, and others got me thinking about a question that I’ve been pondering for quite a while now. Can data be a public infrastructure?
Of course, an answer to such a broad question can only be one: it depends.
Why this matters
Naming data a public infrastructure matters for a bunch of reasons.
First, infrastructure is often non-rival and has positive externalities that are not easily captured, and yet it requires high sunk costs. This calls for public intervention to avoid under-investment in costly but critical infrastructures. Second, it has implications for how certain data should be managed. Generally, if data plays a systemic role - think about the data on energy demand and supply to operate the electric grid - we need to ensure that it’s trustworthy and always “on”. Lastly, because we all depend on infrastructures for many other things, they need to remain accessible, though not necessarily open. More on this last point later.
The infrastructural traits of data
Defining infrastructure is already tricky.1 Naming “public” infrastructure, especially when the asset is digital, adds another layer of complexity. This paper by Mariana Mazzucato, Dave Eaves, and Beatriz Vasconcellos at IIPP, and this one written jointly by IIPP at UCL and the Bennett Institute at Cambridge University go deep into how we can think about “infrastructure” and “public” in the digital world.
In the case of data, there are at least five characteristics that can make certain data an infrastructure: non-rivalry, positive externalities, high sunk costs, systemic risks, and need for neutrality and trust.

A national census or a land registry has all these traits, and therefore, the role of the government is to collect, manage, and steward this “single source of truth” to enable the economy to operate smoothly by having trust in the veracity and accuracy of the data, and favoring a wide access to it. Some operational aspects of the system may be outsourced, but the overall control of the data and its access rules are the government’s responsibility. Other datasets, such as real-time public transport feeds, although a side-product generated while providing a service, can too be conceived as authoritative data registries that act as public infrastructure.
Corporate datasets can also qualify as infrastructure
The problem is that just because some data meet these criteria does not automatically mean that they should become public registries run by the government. There are corporate datasets that have these features, too, and are not government owned. Take Experian, for example. This company collects and aggregates information on more than 1 billion people and businesses. This data is used by companies and financial institutions to make decisions on multiple economic transactions.
How does this corporate data map onto our 5 infrastructural characteristics?
Non-rivalry: Multiple lenders, landlords, and insurers can query the same consumer file simultaneously without “using it up.” The same credit report serves thousands of decisions at once.2
Positive externalities: A comprehensive and accurate credit history reduces default risk across all lenders, lowers borrowing costs, and streamlines rental and employment screening.
High sunk costs: Building nationwide credit histories requires decades of record-keeping, complex de-duplication, and legal compliance; once established, it’s prohibitively expensive to replace.
Systemic risk: An outage or data corruption at Experian would freeze credit approvals, halt mortgage originations, and cascade through consumer finance markets.
Need for neutrality and trust: Lenders and regulators demand that scoring algorithms and data-validation processes be transparent, auditable, and free from discriminatory bias.
Of course, this need for neutrality and potential systemic risk has its implications for how this data collected and managed by a company should be run. That is when the government steps in: through laws such as the Fair Credit Reporting Act, this data is subject to regulations akin to a public utility related to accuracy, nondiscrimination, auditability, and consumer access.
When the flow is the asset
So both government and corporate datasets can be “infrastructural” and therefore subject to either government management or regulation.
There are other cases where the public value does not lie in a particular dataset, but the flow of the data. Here, the government seeks to ensure that data flows seamlessly among entities by establishing interoperability and sharing mandates through APIs, standards, etc. Usually the goal is to promote the positive externalities that come from data sharing on innovation, better services, as well as to avoid the risky dependence on entities that may have captured the data layer through vertical integration or by eliminating the competence. In other cases, the goal for ensuring the flow of data may be better traffic management or increased road safety. The EU’s regulations on real-time traffic and safety data fall under this category.
To guarantee the data flow, the government may want to run the technological layer itself. Think about the famous Estonian X-Road or other data exchange mechanisms. This paper by the Center for Public Digital Infrastructure offers great detail. Yet, the Government may not need to own and manage the “pipes,” as long as the flow of data is secured.
Going back to the paper by Mazzucato, Eaves, and Vasconcellos, we can map this distinction to their “Stack”: data assets at the bottom, data flows in the middle layer.

Infrastructure doesn’t equal Open
An important point to keep in mind is that calling something an infrastructure does not make it automatically open to everybody. We may want to protect certain data assets or flows because of the role they play in the economy or to run the government, but deciding who can access that data, and in what terms, demands other considerations: the incentives and costs of producing the data and opening it, potential privacy risks, impact on competition, and the public value that can be generated.
In other words, a dataset can be infrastructural and still restricted (energy grid data), or non-infrastructural yet fully open (city bike-share trips).
Different roles for different purposes
Not all data are created equal, and thus there’s no single approach to dealing with data assets or flows that are public infrastructures.
I see at least eight different roles for the government. We can map them on a simple grid. On one axis sits the public goal: keeping the data itself accurate and trustworthy, making it accessible, ensuring there are common pipes for data to flow, or keeping the pipes running. On the other axis sits who is best placed to steward that priority: the government or a regulated private actor.
Where a dataset or data flow lands in this grid points us directly to the right policy lever.
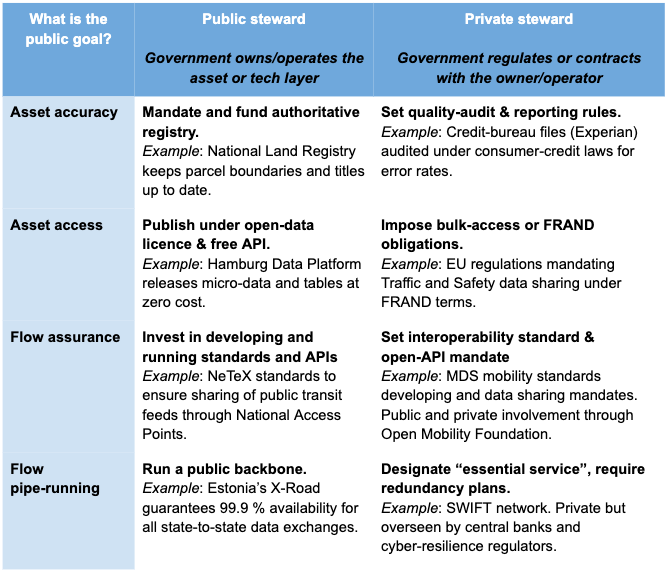
Where does this leave us?
At the very least, recognising that, while useful, labelling data ‘a public infrastructure’ is only the first diagnostic. The treatment will depend on which goal is pursued and where the bottleneck sits: the dataset or the pipes.
For a different, yet inspiring use of the “infrastructure” concept, see Stefan Verhulst in Inquiry as Infrastructure: Defining Good Questions in the Age of Data and AI (2024): “the questions are infrastructures of meaning. What we ask shapes not only what data we collect or what models we build but also what values we uphold and what futures we make possible.”
Access, however, can be rival due to API rate limits or bandwidth constraints.